1. Код с проверкой на четность.
Такой
код образуется путем добавления к
передаваемой комбинации, состоящей из k
информационных символов, одного
контрольного символа (0 или 1), так, чтобы
общее число единиц в передаваемой
комбинации было четным.
Пример
5.1.
Построим коды для проверки на четность, где k
-
исходные комбинации, r
-
контрольные символы.
| k | r |
n |
| 11011 | 0 | 110110 |
| 11100 | 1 | 111001 |
Определим, каковы обнаруживающие свойства
этого кода. Вероятность Poo
обнаружения ошибок будет равна
![]()
Так как вероятность ошибок
![]() является
весьма малой величиной, то можно
ограничится
является
весьма малой величиной, то можно
ограничится
![]()
Вероятность
появления всевозможных ошибок, как
обнаруживаемых так и не обнаруживаемых,
равна
![]() ,
где
,
где
![]() -
вероятность отсутствия искажений в кодовой
комбинации. Тогда
-
вероятность отсутствия искажений в кодовой
комбинации. Тогда
![]() .
.
При
передаче большого количества кодовых
комбинаций Nk
, число кодовых
комбинаций, в которых ошибки
обнаруживаются, равно:
![]()
Общее
количество комбинаций с обнаруживаемыми и
не обнаруживаемыми ошибками равно
![]()
Тогда
коэффициент обнаружения Kобн
для кода с четной защитой будет равен
![]()
Например,
для кода с k=5
и вероятностью ошибки
![]() коэффициент
обнаружения составит
коэффициент
обнаружения составит
![]() . То есть 90% ошибок
обнаруживаем, при этом избыточность будет
составлять
. То есть 90% ошибок
обнаруживаем, при этом избыточность будет
составлять
![]() или
17%.
или
17%.
2. Код с постоянным весом.
Этот
код содержит постоянное число единиц и
нулей. Число кодовых комбинаций составит
![]()
Пример 5.2. Коды с двумя единицами из пяти и
тремя единицами из семи.
|
|
|
| 11000
10010 00101 |
0000111
1001001 1010100 |
Этот код позволяет обнаруживать любые одиночные ошибки и часть многократных ошибок. Не обнаруживаются этим кодом только ошибки смещения, когда одновременно одна единица переходит в ноль и один ноль переходит в единицу, два ноля и две единицы меняются на обратные символы и т.д.
Рассмотрим код с тремя единицами из семи. Для этого кода возможны смещения трех типов.
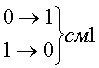
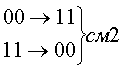
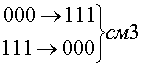
Вероятность появления не обнаруживаемых ошибок смещения
![]() , где
, где
![]()
![]()
![]()
При
p<<1
![]() , тогда
, тогда
![]()
Вероятность
появления всевозможных ошибок как
обнаруживаемых, так и не обнаруживаемых
будет составлять
![]()
Вероятность
обнаруживаемых ошибок
![]() . Тогда
коэффициент обнаружения будет равен
. Тогда
коэффициент обнаружения будет равен
![]()
Например,
код
![]() при
при
![]() коэффициент обнаружения составит
коэффициент обнаружения составит
![]() ,
избыточность L=27%.
,
избыточность L=27%.
3.
Корреляционный код
(Код с удвоением). Элементы
данного кода заменяются двумя символами,
единица ‘1’ преобразуется в 10, а ноль ‘0’ в
01.
Вместо комбинации 1010011
передается 10011001011010.
Ошибка обнаруживается в том случае, если в
парных элементах будут одинаковые символы
00 или 11 (вместо 01 и 10).
Например,
при k=5,
n=10
и вероятности ошибки
![]() ,
,
![]() .
Но при этом избыточность будет
составлять 50%.
.
Но при этом избыточность будет
составлять 50%.
4. Инверсный код. К исходной комбинации добавляется такая же комбинация по длине. В линию посылается удвоенное число символов. Если в исходной комбинации четное число единиц, то добавляемая комбинация повторяет исходную комбинацию, если нечетное, то добавляемая комбинация является инверсной по отношению к исходной.
| k | r |
n |
| 11011 | 11011 | 1101111011 |
| 11100 | 00011 | 1110000011 |
Прием
инверсного кода осуществляется в два этапа.
На первом этапе суммируются единицы в
первой основной группе символов. Если число
единиц четное, то контрольные символы
принимаются без изменения, если нечетное,
то контрольные символы инвертируются. На
втором этапе контрольные символы
суммируются с информационными символами по
модулю два. Нулевая сумма говорит об
отсутствии ошибок. При ненулевой сумме,
принятая комбинация бракуется. Покажем
суммирование для принятых комбинаций без
ошибок (1,3) и с ошибками (2,4).
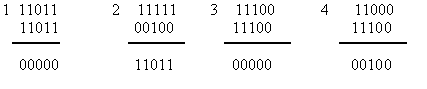
Обнаруживающие способности
данного кода достаточно велики. Данный код
обнаруживает практически любые ошибки,
кроме редких ошибок смещения, которые
одновременно происходят как среди
информационных символов, так и среди
соответствующих контрольных. Например, при k=5, n=10
и
![]() . Коэффициент обнаружения будет
составлять
. Коэффициент обнаружения будет
составлять
![]() .
.
5. Код Грея. Код Грея используется для преобразования угла поворота тела вращения в код. Принцип работы можно представить по рис.5.2. На пластине, которая вращается на валу, сделаны отверстия, через которые может проходить свет. Причём, диск разбит на сектора, в которых и сделаны эти отверстия. При вращении, свет проходит через них, что приводит к срабатыванию фотоприёмников. При снятии информации в виде двоичных кодов может произойти существенная ошибка. Например, возьмем две соседние цифры 7 и 8. Двоичные коды этих цифр отличаются во всех разрядах.
7 0111
-> 1111
8 1000
->
0000
Если ошибка произойдет в старшем разряде,
то это приведет к максимальной ошибке, на 3600.
А код Грея,
это такой код в котором все соседние
комбинации отличаются только одним
символом, поэтому при переходе от
изображения одного числа к изображению
соседнего происходит изменение только на
единицу младшего разряда. Ошибка будет
минимальной.
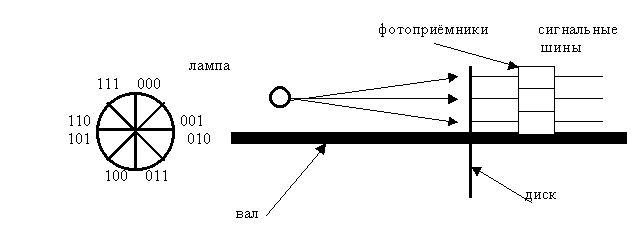
Рис.5.2. Схема съема информации угла поворота вала в код
Код Грея записывается следующим образом
| Номер | Код Грея |
| 0 | 0 0 0 0 |
| 1 | 0 0 0 1 |
| 2 | 0 0 1 1 |
| 3 | 0 0 1 0 |
| 4 | 0 1 1 0 |
| 5 | 0 1 1 1 |
| 6 | 0 1 0 1 |
| 7 | 0 1 0 0 |
| 8 | 1 1 0 0 |
| 9 | 1 1 0 1 |
| 10 | 1 1 1 1 |
| 11 | 1 1 1 0 |
| 12 | 1 0 1 0 |
| 13 | 1 0 1 1 |
| 14 | 1 0 0 1 |
| 15 | 1 0 0 0 |
Разряды
в коде Грея не имеют постоянного веса. Вес k-разряда
определяется следующим образом
![]()
При этом все нечетные единицы, считая слева направо, имеют положительный вес, а все четные единицы отрицательный.
Например,
![]()
Непостоянство
весов разрядов затрудняет выполнение
арифметических операций в коде Грея,
поэтому необходимо уметь делать перевод
кода Грея в обычный двоичный код и наоборот.
Алгоритм перевода чисел можно представить
следующим образом.
Пусть
![]() -- двоичный код,
-- двоичный код,
![]() -- код Грея
-- код Грея
Тогда переход из двоичного кода в код Грея выполнится по следующему алгоритму
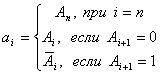
Например,
![]() .
.
Обратный переход из кода Грея в двоичный код
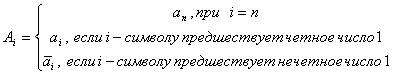
![]()
Например,
![]() .
.